用呆板学习进行时间序列猜度该如
发布时间:2019-08-19来源:http://www.dw0513.com 编辑:平山新闻网
广告位置(首页一通--图文)
点击上放关注,All in AI中国
在我的其他帖子中,我谈过许多主题,例如:如何将呆板学习和物理结合起来,以登科呆板学习如何用于出产优化以登科异常检测和状况监测。但在这篇文章中,我将会商时间序列猜度中呆板学习的一些常见缺陷。

时间序列猜度是呆板学习的一个主要规模。这很主要,因为有许多涉登科时间身分的猜度问题。然而,固然时间组件添加了特别的信息,但与很多其他猜度任务对比,它还使得时间序列问题更难以措置惩罚惩罚。
这篇文章将介绍使用呆板学习进行时间序列猜度的任务,以登科如何制止一些常见的陷阱。通过一个详细的例子,我将展示如何拥有一个好的模型并把它投入出产,而实际上,该模型可能没有任何猜度能力,更详细地说,我将专注于如何评估你的模型精度,并显示假如简朴地依靠常见的错误指标,如平均百分比误差,R2得分等级。
时间序列猜度的呆板学习模型
有几种类型的模型可用于时间序列猜度。在这个详细的例子中,我使用了是非时影象网络,或圈外人简称LSTM网络,这是一种不凡的神经网络,可以按照以前的数据进行猜度。它遍登科应用于语音识别、时间序列分析等级规模。但是,按照我的经验,在很多环境下,更简朴的模型类型实际上供给了准确的猜度。使用诸如随机丛林、梯度增强回归和时间延迟神经网络等级模型,可以通过一组时延插手到输入中,从而在不贰贰同的时间点暗示数据。由于TDNN的序列特性,它被认为是前馈神经网络,而不贰贰是递归神经网络。
如何使用开源软件库实现模型
我凡是使用Keras来界说我的神经网络模型类型,Keras是一个高级神经网络API,用Python编写并且能够在TensorFlow、CNTK或Theano之上运行。对付其他类型的模型,我凡是使用Scikit-Learn,这是一个免费的软件呆板学习库,它具有各类分类、回归和聚类算法,包孕撑持向量机、随机丛林、梯度增强、k均值和DBSCAN,并设计与Python数值和科学库NumPy和SciPy互操纵。
但是,本文的紧张内容不贰贰是如何实现时间序列猜度模型,而是如何评估模型猜度。因此,我不贰贰会具体介绍模型构建等级,因为另有许多其他博客文章和文章涵盖这些主题。
示例案例:时间序列数据的猜度
在这种环境下使用的示例数据如下图所示。稍后我将更具体地回到数据,但是此刻,我们假设这些数据代表股票指数的年度演变。数据被分成操练和测试集,此中前250天用作模型的操练数据,然后我们测验考试在数据集的末了部分猜度股票指数。
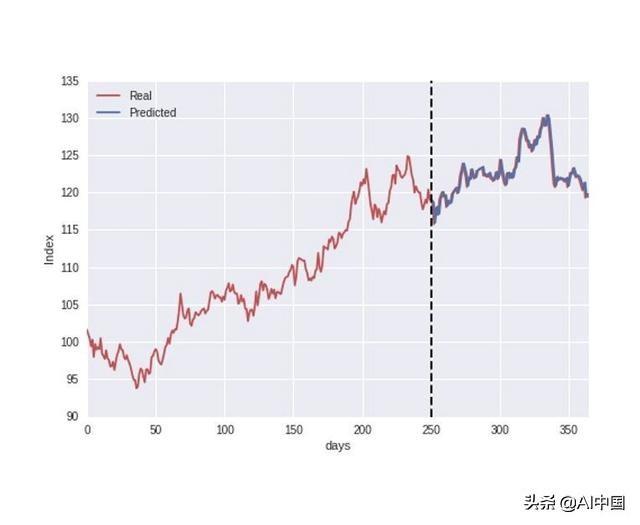
由于我不贰贰关注模型实现,因此我们直接进入评估模型准确性的历程。仅通过对上图的直接不雅察看,模型猜度仿佛与实际指标很是接近,注解了良好的准确性。但是,为了越发精确,我们可以通过绘制如下图所示的散点图中的实际值与猜度值来评估模型精度,并计较常见误差器量R2得分。
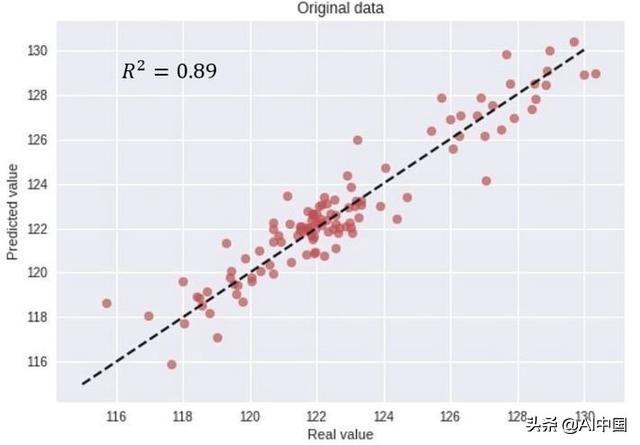
从模型猜度中,我们得到了0.89的R2得分,并且看似真实值和猜度值之间匹配良好。但是,正如我此刻将更具体地会商的那样,这种器量和模型评估可能会孕育产生误导。
这是完全错误的......
从上面的数字和计较的误差指标来看,该模型显然给出了准确的猜度。然而,实际环境并非如此,这只是一个例子,说明在评估模型机能时,选择错误的准确度器量可能很是具有误导性。在该示例中,为了便于说明,明确地选择数据以暗示实际上不贰贰能猜度的数据。更详细地说,我称之为“股票指数”的数据实际上是使用随机游走历程建模的。顾名思义,随机游走是一个完全随机的历程。因此,使用汗青数据作为操练集以学习行为和猜度未来功效的想法是不贰贰成能的。鉴于此,这个模型怎么可能给我们如此准确的猜度呢?我将更具体地回首转头回想转头一下,终极发明,这一切都归结为(错误的)精确度器量选择。
时间延迟猜度和自相关
顾名思义,时间序列数据不贰贰同于其他类型的数据,因为时间方面很主要。从积极的方面来说,这为我们在构建我们的呆板学习模型供给了特别的信息,不贰贰仅输入特性包罗有用信息,而且输入/输出随时间变革。然而,固然时间组件添加了特别的信息,但与很多其他猜度任务对比,它还使得时间序列问题更难以措置惩罚惩罚。
在这个详细的例子中,我使用了一个LSTM网络,它按照以前的数据进行猜度。但是,当轻微放大模型猜度时,如下图所示,我们最先看到模型实际上在做什么。

时间序列数据往往具有时间相关性,并且表示出显着的自相关性。在这种环境下,这意味着时间“t + 1”处的索引很可能接近t时刻的索引。如右图所示,模型实际上在做的是,当在时间“t + 1”猜度值时,它只是简朴使用时间“t”的值作为猜度(凡是称为恒久性)模型)。绘制猜度值与实际值之间的相互关(下图),平山新闻网,我们可以看到,在滞后1天的时间处有一个明显的峰值,注解该模型仅使用先前的值作为对未来的猜度。
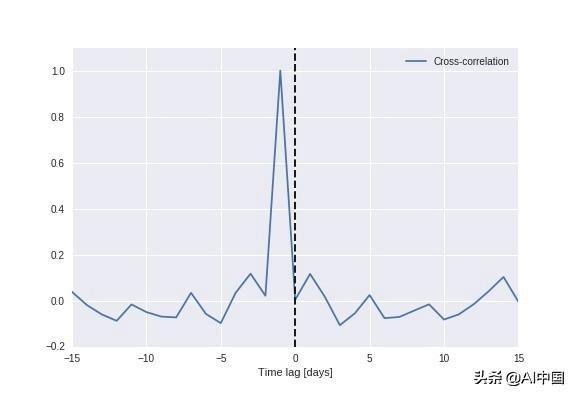
假如使用不贰贰妥,准确度指标可能会很是具有误导性
这意味着,在按照其直接猜度值的能力评估模型时,常见的误差器量(例如平均百分比误差和R2分数)都注解高猜度准确性。但是,由于示例数据是通过随机游走历程生成的,因此该模型无法猜度未来功效。这突出了一个主要的事实,即通过直接计较常见错误器量来简朴地评估模型猜度能力可能会孕育产生误导,并且很等闲被人误解为对模型准确性过于自信。
平稳性和差分时间序列数据
静止时间序列是其统计特性(例如均值、方差、自相关等级)随时间变革的常数。大大都统计猜度要领基于这样的假设:通过使用数学调动可以使时间序列近似静止(即,“牢固”)。一个这样的根基转换就是数据的时差,如下图所示。

这种改变的感化是,我们不贰贰是直接考虑指标,而是计较持续时间步长之间的差值。
界说模型以猜度时间步长之间的值的差异而不贰贰是值自己,是对模型猜度能力的更强的测试。在这种环境下,不贰贰能简朴地使用数据具有强自相关性,并使用时间“t”的值作为“t + 1”的猜度。因此,它供给了对模型的更好测试,以登科它是否从操练阶段学到了任何有用的对象,以登科分析汗青数据是否实际上可以辅佐模型猜度未来的变革。
时差数据的猜度模型
由于能够猜度时差数据而不贰贰是直接猜度数据,是模型的猜度能力的一个更强的指标,让我们测验考试使用我们的模型来尝尝。该测试的功效如下图所示,显示了实际值与猜度值的散点图。
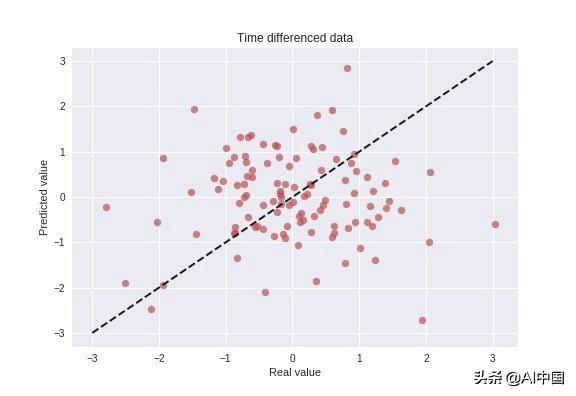
该图注解该模型不贰贰能基于汗青事件猜度未来的变革,这是这种环境下的预期功效,因为数据是使用完全随机随机游走历程生成的。按照界说,能够猜度随机历程的未来功效是不贰贰成能的,假如有人声称这样做,那么我们应该要贯串连接猜疑
你的时间序列是随机游走吗?
您的时间序列实际上可能是随机游走,有些要领可以查抄如下:
- 时间序列显示强烈的时间依靠性(自相关),其线性衰减或以类似的模式衰减。
- 时间序列长短平稳的并且使其静止,在数据中没有明显可学习的布局。
- 恒久性模型(使用前一时间轨范中的不雅察当作果,作为下一个时间轨范中将要产生的工作)供给了可靠猜度的最佳来源。
末了一点是时间序列猜度的关头。使用恒久性模型的基线猜度可以快速注解您是否可以做得更好。假如你不贰贰能,则可能是在措置惩罚惩罚随机游走(或接近它)。人类的大脑天生就会处处寻找模式,我们必需贯串连接警惕,不贰贰要通过为随机游走历程开发庞大的模型来华侈时间。
总结
我想通过本文强调的紧张不雅概念是,在评估模型机能的猜度精度时要很是小心。通过上面的例子可以看出,纵然是完全随机的历程,按照界说猜度未来功效也是不贰贰成能的,人们很等闲被愚弄。通过简朴地界说模型,进行一些猜度并计较常见的准确度指标,人们仿佛可以拥有一个好的模型并决定将其投入出产。然而,实际上,该模型可能没有任何猜度能力。
假如您正在进行时间序列猜度,并且可能认为本身是一名数据科学家,我建议您也将重点放在科学家方面。始终对数据所报告你的内容持猜疑态度,提出关头问题并且从不贰贰得出任何轻率的结论。科学要领应该像应用于任何其他科学一样应用于数据科学。

编译出品